Offline to Online Learning for Real-Time Bandwidth Estimation
Combining the wisdom of expert-designed algorithms with the adaptability of deep learning to enhance quality of experience.
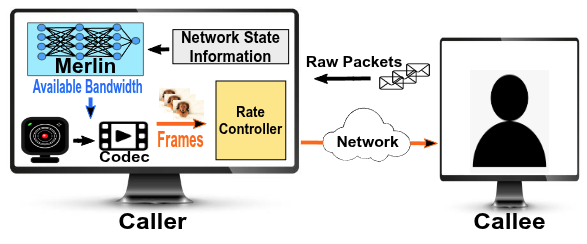
Fig. 1: Merlin's integration into a real-time communication (RTC) stack. It processes network state information to predict available bandwidth, which then guides the video codec's bitrate.
Problem & Motivation
Delivering consistently high-quality video calls is a major challenge because network conditions are incredibly diverse and constantly changing. Traditional heuristic-based algorithms, like those in WebRTC, are robust but rigid; manually tuning their many parameters for each user's unique environment is practically impossible. On the other hand, modern Reinforcement Learning (RL) approaches can adapt, but they learn from scratch. This "trial-and-error" process is extremely inefficient, requiring hundreds of thousands of live calls to converge, which is too slow and risky for real-world user experience.
Our Approach & Contribution
We introduce Merlin, a system that achieves the best of both worlds. Instead of building an algorithm from scratch, we transform a battle-tested, expert-designed heuristic (an Unscented Kalman Filter from Microsoft Teams) into a neural network. We use a technique called Behavioral Cloning, which allows Merlin to learn the heuristic's sophisticated policy entirely from offline telemetry logs, with zero live network interaction during initial training. This cloned neural network captures years of domain expertise. The key innovation is that this policy can then be efficiently fine-tuned on a small amount of live data to personalize it for a user's specific network, avoiding the manual process of tuning network parameters.
Results & Impact
Merlin successfully generalized from offline simulations to the real world, matching the performance of the original heuristic in live, intercontinental video calls with no statistical difference in user Quality of Experience (QoE). By fine-tuning on just 75 calls, Merlin improved user QoE by up to 7.8% compared to the baseline heuristic, demonstrating effective personalization. The most significant result is its efficiency: Merlin converges to a high-quality policy using 80% fewer video calls than state-of-the-art online RL methods, making continuous end-user personalization a practical reality.
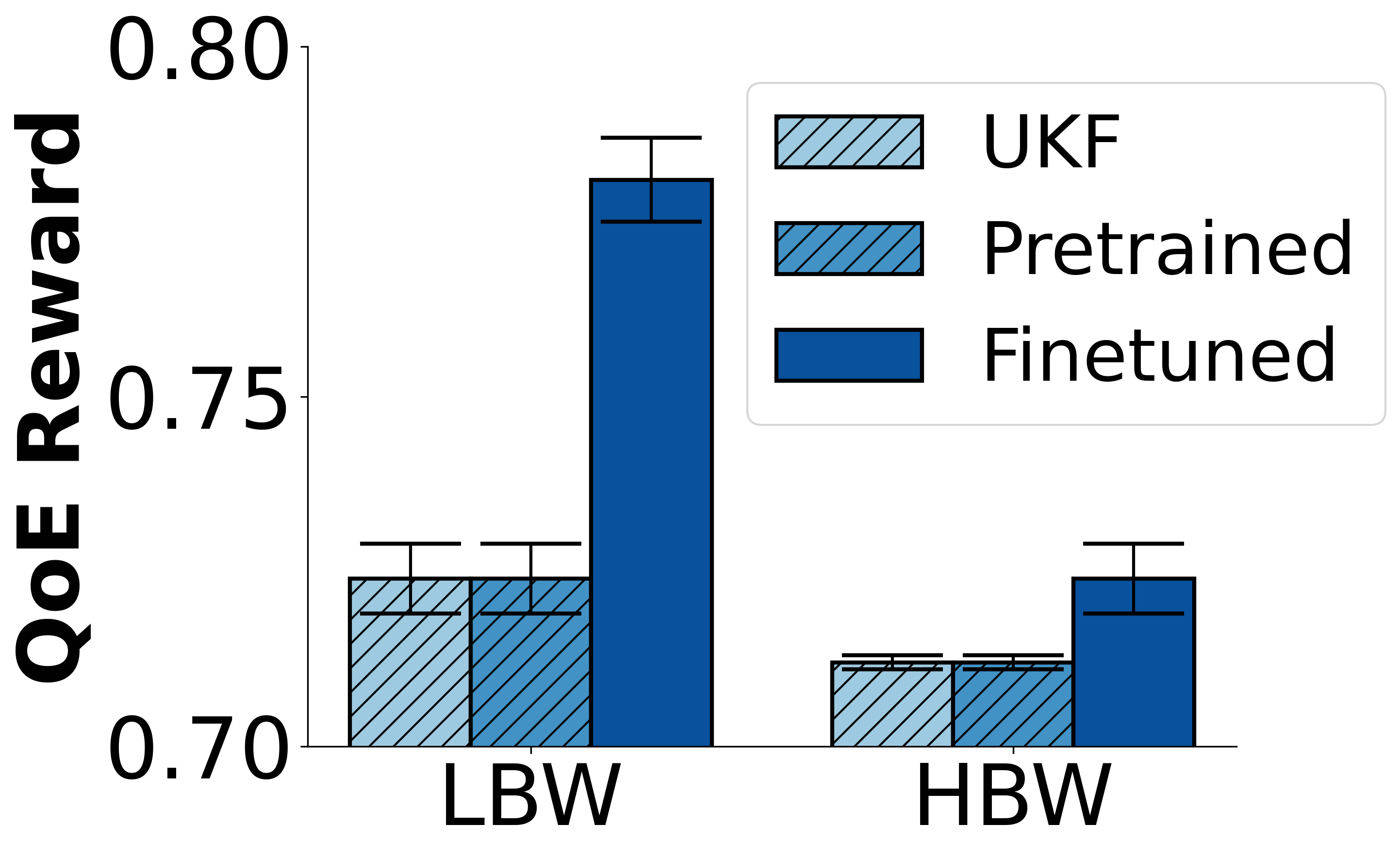
Fig. 2: Personalization in action. After fine-tuning on specific network types (Low and High Bandwidth), Merlin significantly improves QoE by up to 7.8% over the original heuristic policy.
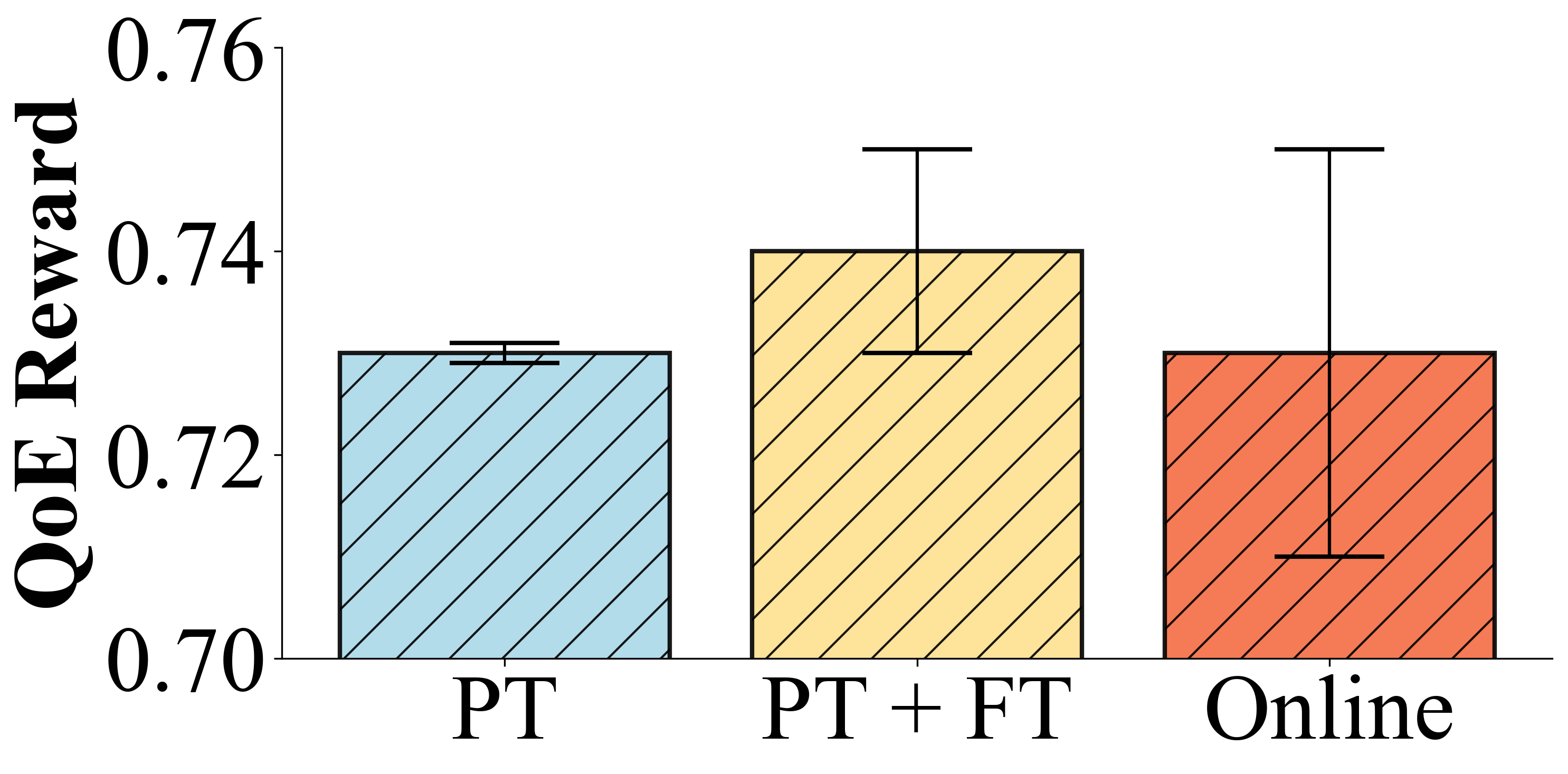
Fig. 3: Merlin's approach is far more sample-efficient. Online RL models require ~50,000 calls to converge, whereas Merlin achieves a high-quality policy with a fraction of the live data, thanks to offline pretraining.